Parsing XML Data: Understanding DOM and SAX Parsers in Java
Hello future software engineers! You’ve successfully learned how to structure and validate XML documents. Now, a critical question arises: how do computer programs actually read, interpret, and work with all this structured XML data? This is where parsing XML data comes in, and in Java, two primary approaches dominate: the Document Object Model (DOM) parser and the Simple API for XML (SAX) parser. Understanding these XML parsing techniques is essential for developing robust applications that interact with XML.
What is an XML Parser?
An XML parser is a software library or component designed to read an XML document and provide programmatic access to its content and structure. Essentially, it acts as an interpreter, translating the raw XML text into a format that a programming language, such as Java, can easily understand and manipulate. A good parser not only reads the data but also checks if the XML document is “well-formed” (adhering to basic XML syntax rules) and optionally “valid” (conforming to a DTD or XML Schema).
There are fundamentally two categories of XML parsers: tree-based parsers and event-based parsers. The DOM parser is a classic example of the former, while the SAX parser exemplifies the latter. Each type offers distinct advantages and disadvantages depending on the specific application requirements, especially when dealing with varying XML document sizes.
1. Document Object Model (DOM) Parser: A Tree-Based Approach
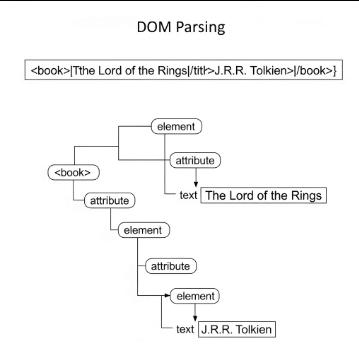
The Document Object Model (DOM) parser is a tree-based API. This means that when it processes an XML document, it loads the entire document into memory and constructs a hierarchical, tree-like structure. Every element, attribute, and even the text content within the XML document becomes a “node” in this in-memory tree.
How the DOM Parser Works
When a Java application utilizes a DOM parser to process an XML file, the parser first reads the entire document from start to finish. Following this, it builds a complete, in-memory representation of the XML as a Document Object Model (DOM) document object. Consequently, every part of the original XML, from the root element to the smallest text node, is represented as an object in this tree.
Once the entire XML document is loaded and transformed into this DOM tree, the Java application can then interact with it using the DOM API. Developers can easily navigate this tree, directly accessing any specific node, element, or attribute without having to sequentially process the entire document. For example, a program can directly jump to find a specific <book> element, or retrieve the id attribute of a particular <student> element, irrespective of its position.
Key Features of the DOM Parser
The DOM parser offers several significant characteristics for parsing XML data:
- Tree-Based Structure: DOM organizes the XML content as a hierarchical tree of nodes, reflecting the nesting of XML elements. This visual representation often makes it intuitive for developers to understand the document’s structure programmatically.
- In-Memory Representation: The entire XML document resides in the computer’s RAM. Therefore, the DOM provides a complete, accessible snapshot of the document at any given moment.
- Read and Write Operations: A crucial advantage of the DOM is its comprehensive support for both reading and modifying XML documents. You can extract data, as well as add new elements, delete existing ones, change content, or update attribute values, and then save the modified tree back as an XML file.
- Random Access Capability: The DOM allows for direct, non-sequential access to any part of the XML document. This is highly beneficial when your application needs to access widely separated pieces of information or re-read parts of the document multiple times.
Advantages of Using the DOM Parser for XML Processing
The DOM parser provides distinct benefits for certain XML parsing scenarios:
- Ease of Manipulation: The DOM’s in-memory tree structure makes it incredibly flexible for modifying the XML document. Developers can easily insert, delete, or update any node within the tree.
- Intuitive API: For developers familiar with object-oriented programming concepts, the DOM API is generally straightforward to learn and use. Navigating and querying the document feels natural and logical.
- Random Data Access: When your application requires the ability to jump directly to specific sections of an XML document without sequential processing, DOM excels.
Disadvantages of the DOM Parser
Despite its strengths, the DOM parser also presents notable drawbacks:
- Memory Inefficiency: This is its most significant limitation. Since the entire XML document must be loaded into memory, DOM can consume a very substantial amount of RAM. Consequently, it becomes impractical or even impossible for processing extremely large XML files (e.g., those hundreds of megabytes or gigabytes in size), often leading to
OutOfMemoryError. - Slower for Large Documents: Building the complete in-memory tree for very large XML files takes time. Therefore, the DOM parser can be comparatively slower during initialization than other parsing methods, particularly event-based ones.
2. SAX (Simple API for XML) Parser: An Event-Driven Approach
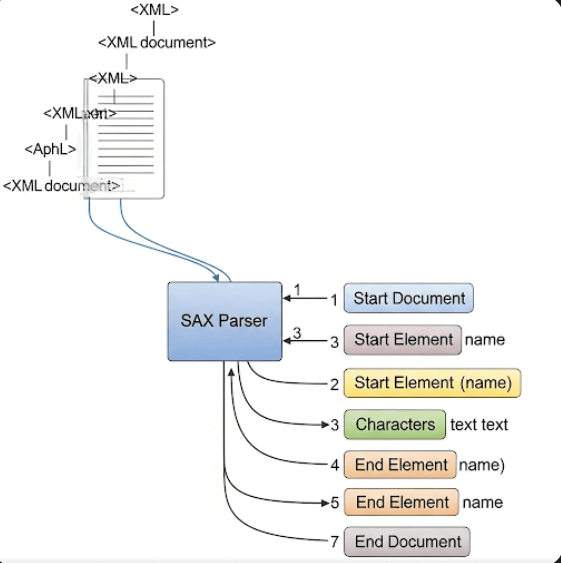
In contrast to the DOM’s tree-based model, the SAX (Simple API for XML) parser is an event-based parser. This means it does not load the entire XML document into memory or build an internal tree structure. Instead, it reads the XML document sequentially, from beginning to end, and triggers specific “events” as it encounters different parts of the XML.
How the SAX Parser Works
A SAX parser operates by reading the XML document in a stream-like fashion. As it encounters various components—such as the start of an element, the end of an element, or character data—it generates corresponding events. Your Java application then needs to implement specific “event handlers” (methods) to respond to these events. For example, when the parser encounters an opening tag like <book>, it calls your startElement() method. When it finds a closing tag like </book>, your endElement() method is triggered. You write custom code within these methods to extract or process the data as it flows past.
This sequential processing means that a SAX parser only holds a small portion of the XML document in memory at any given time. Consequently, it’s highly efficient in terms of memory usage.
Key Features of the SAX Parser
The SAX parser offers unique characteristics for parsing XML data:
- Event-Based Processing: SAX operates by triggering events. Developers write callback methods that are executed when specific XML constructs (like tags or text) are encountered.
- No Internal Structure: Unlike DOM, SAX does not build an in-memory tree representation of the XML document. This is its core differentiator and source of efficiency.
- Forward-Only Access: SAX processes the XML document sequentially from start to finish. You cannot go back to a previously processed part of the document, nor can you jump directly to a specific element.
Advantages of the SAX Parser for XML Processing
The SAX parser offers compelling benefits, particularly for specific XML parsing tasks:
- Memory Efficiency: This is the most significant advantage of SAX. Because it processes the document in a streaming fashion without loading the entire content into memory, it is extremely memory-efficient. This makes SAX ideal for processing very large XML files where DOM would cause memory issues.
- High Performance: Since it doesn’t need to build and manage a complex internal tree structure, SAX is generally much faster than DOM for reading and extracting data from XML documents.
- Suitable for Large Documents: SAX excels in scenarios where you need to process large XML files, especially when you only need to extract specific information without needing the entire document structure in memory.
Disadvantages of the SAX Parser
Despite its efficiency, the SAX parser does have some drawbacks:
- Less Intuitive API: The event-based nature of SAX can be more complex to work with compared to the DOM’s tree-like navigation. Developers often need to manage the context of the data themselves (e.g., knowing the parent of a current element).
- Read-Only Operation: SAX is primarily designed for reading XML data. It is not suitable for modifying the XML document’s structure, as it provides no mechanism to write back to the XML stream or manipulate the parsed data in a persistent tree.
- No Random Access: Due to its sequential nature, you cannot directly access a specific element without processing all the data that comes before it. If you need to re-read a part of the document, you typically have to parse the entire document again from the beginning
Choosing Between DOM and SAX Parsers in Java
The choice between a DOM parser and a SAX parser in Java for parsing XML data largely depends on your application’s specific requirements:
- Choose DOM when:
- The XML document is relatively small and can comfortably fit into your application’s memory.
- You require random access to or need to navigate different, non-sequential parts of the document.
- You need to modify the XML document’s structure (add, delete, update elements) after parsing.
- Choose SAX when:
- The XML document is very large, and memory efficiency is a critical concern.
- You only need to read data from the XML document (no modifications).
- You can process the data sequentially as it comes in, without needing the full document context.
Both DOM and SAX are powerful and widely used tools for working with XML data in Java. Understanding their fundamental differences and their respective strengths and weaknesses will empower you to select the most efficient and appropriate XML parsing approach for your programming projects in Web Technologies.