Document Object Model (DOM): Navigating XML as a Tree
Hello everyone! We’ve discussed how XML structures data and how schemas validate it. Now, let’s explore how computer programs actually access and manipulate this structured XML data. This brings us to the Document Object Model (DOM), a powerful programming interface that treats your entire XML document like a well-organized family tree.
What is the Document Object Model (DOM)?
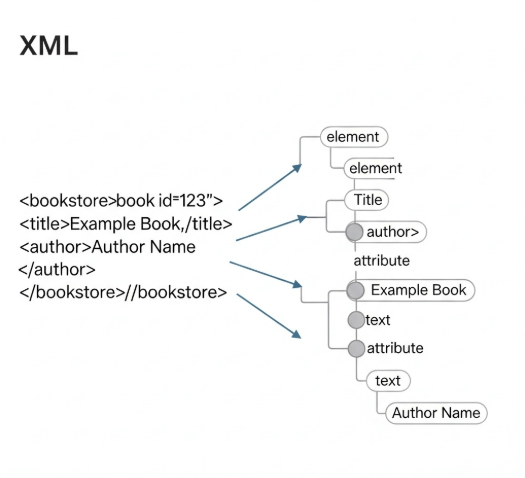
The Document Object Model (DOM) is a programming interface (API) for HTML and XML documents. It defines the logical structure of documents and the way a document is accessed and manipulated. Simply put, when an XML document is loaded into a DOM parser, the parser converts the entire document into a tree-like structure in your computer’s memory. Every element, attribute, and piece of text in the XML document becomes a “node” in this tree.
For instance, consider a simple XML file. The DOM parser reads the entire file, then constructs a hierarchical model of it. This model allows developers to treat the XML document as a collection of objects, making it easy to programmatically access, modify, add, or delete elements and attributes. Essentially, the DOM provides a standard way for programs to interact with the content, structure, and style of XML documents.
How Does the DOM Parser Work?
A DOM parser (a software component that implements the DOM API) meticulously reads the entire XML document. It then builds a complete, in-memory representation of this document as a tree structure. Each component of the XML document—such as the root element, child elements, attributes, and even the text content—is transformed into a node in this tree.
Once the entire XML document is loaded and converted into this DOM document object in memory, client applications can then interact with it. They achieve this by invoking various methods on this document object. For example, a program can easily ask for “the first child of the root element,” or “all elements with the tag name ‘book’,” or “the value of an attribute named ‘id’.” This capability for direct, random access is a core strength of the DOM.
Key Features of the Document Object Model (DOM)
The DOM offers several distinct characteristics that make it suitable for particular XML processing tasks:
- Tree-Based Structure: Fundamentally, DOM represents your XML document as a hierarchical tree. This visual and logical structure mirrors the nesting of XML elements, making it intuitive for developers to navigate through the document’s content.
- In-Memory Representation: The entire XML document is loaded into the computer’s RAM. Therefore, the DOM provides a complete snapshot of the document at any given time.
- Read and Write Operations: A significant advantage of the DOM is its ability to support both reading and writing (or modifying) operations. You can not only extract data but also add new elements, delete existing ones, change content, or modify attribute values. Afterwards, you can save the modified in-memory tree back to an XML file.
- Random Access: Unlike some other parsing methods, the DOM allows for direct, random access to any part of the XML document. You can jump to a specific element without having to process all preceding elements. This feature is particularly useful when you need to access widely separated parts of a document or re-read parts multiple times.
Advantages of Using the DOM Parser
Given its features, the DOM parser offers several compelling benefits:
- Flexibility for Manipulation: Since it loads the entire document into memory, the DOM provides unparalleled flexibility for modifying the XML structure. For instance, you can easily insert a new element, delete a node, or update content anywhere in the document.
- Ease of Use: The DOM API is generally considered relatively straightforward and intuitive to use, especially for developers familiar with object-oriented programming. Once the tree is built, navigating and querying its components feels quite natural.
- Random Access Capabilities: This is a major advantage for applications that require non-sequential access to data. For example, if you need to fetch specific information from different, non-contiguous parts of a large XML file, DOM handles this efficiently.
Disadvantages of the DOM Parser
Despite its strengths, the DOM also comes with certain limitations:
- Memory Inefficiency: This is the most significant drawback. Because the entire XML document is loaded into memory, DOM can consume a substantial amount of RAM. Consequently, it becomes impractical for processing very large XML files (e.g., hundreds of megabytes or gigabytes) as it might lead to out-of-memory errors.
- Performance for Large Documents: Loading and building the entire tree structure in memory takes time. Therefore, for extremely large documents, the DOM parser can be comparatively slower to initialize than event-based parsers.
In conclusion, the Document Object Model (DOM) provides a robust and flexible way to interact with XML documents, particularly when you need to manipulate their structure or access data non-sequentially. However, for very large files or scenarios where memory efficiency is paramount, other parsing approaches might be more suitable.