Aim: Implementation of Decision tree using sklearn and its parameter tuning
Program:
# Importing the required packages
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# Function to import the dataset
def importdata():
balance_data = pd.read_csv(
'https://archive.ics.uci.edu/ml/machine-learning-databases/balance-scale/balance-scale.data',
sep=',', header=None
)
# Displaying dataset information
print("Dataset Length: ", len(balance_data))
print("Dataset Shape: ", balance_data.shape)
print("Dataset: ", balance_data.head())
return balance_data
# Function to split the dataset into features and target variables
def splitdataset(balance_data):
# Separating the target variable
X = balance_data.values[:, 1:5]
Y = balance_data.values[:, 0]
# Splitting the dataset into train and test
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=100)
return X, Y, X_train, X_test, y_train, y_test
# Function to train the model using Gini index
def train_using_gini(X_train, X_test, y_train):
# Creating the classifier object
clf_gini = DecisionTreeClassifier(criterion="gini", max_depth=3, min_samples_leaf=5)
# Performing training
clf_gini.fit(X_train, y_train)
return clf_gini
# Function to train the model using Entropy
def train_using_entropy(X_train, X_test, y_train):
# Decision tree with entropy
clf_entropy = DecisionTreeClassifier(
criterion="entropy", random_state=100, max_depth=3, min_samples_leaf=5
)
# Performing training
clf_entropy.fit(X_train, y_train)
return clf_entropy
# Function to make predictions
def prediction(X_test, clf_object):
y_pred = clf_object.predict(X_test)
print("Predicted values:")
print(y_pred)
return y_pred
# Function to calculate accuracy
def cal_accuracy(y_test, y_pred):
print("Confusion Matrix: ", confusion_matrix(y_test, y_pred))
print("Accuracy : ", accuracy_score(y_test, y_pred) * 100)
print("Report : ", classification_report(y_test, y_pred))
# Function to plot the decision tree
def plot_decision_tree(clf_object, feature_names, class_names):
plt.figure(figsize=(15, 10))
plot_tree(clf_object, filled=True, feature_names=feature_names, class_names=class_names, rounded=True)
plt.show()
# Main execution
if __name__ == "__main__":
data = importdata()
X, Y, X_train, X_test, y_train, y_test = splitdataset(data)
# Training using Gini Index
clf_gini = train_using_gini(X_train, X_test, y_train)
# Training using Entropy
clf_entropy = train_using_entropy(X_train, X_test, y_train)
# Visualizing the Decision Trees
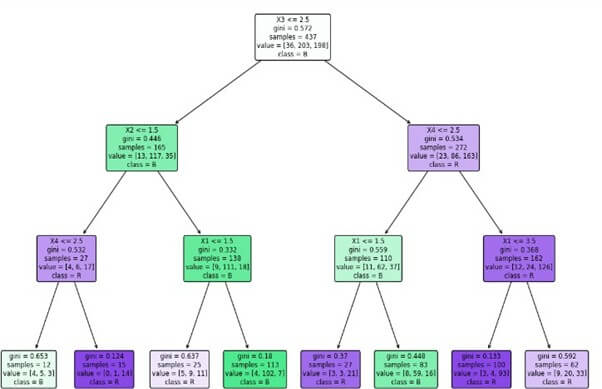
plot_decision_tree(clf_gini, ['X1', 'X2', 'X3', 'X4'], ['L', 'B', 'R'])
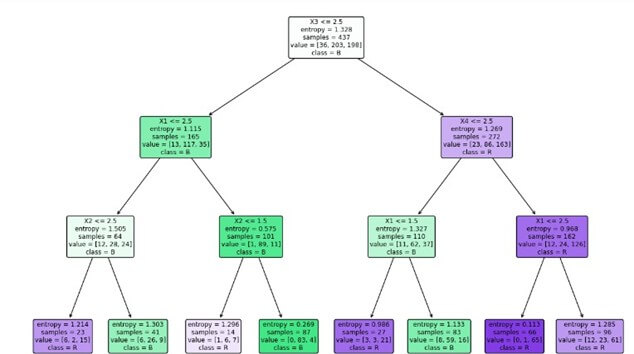
plot_decision_tree(clf_entropy, ['X1', 'X2', 'X3', 'X4'], ['L', 'B', 'R'])
# Operational Phase
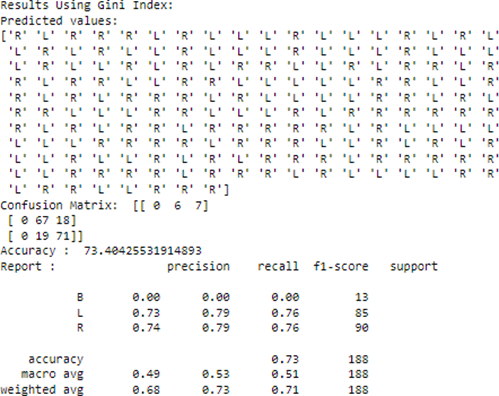
print("Results Using Gini Index:")
y_pred_gini = prediction(X_test, clf_gini)
cal_accuracy(y_test, y_pred_gini)
Output:
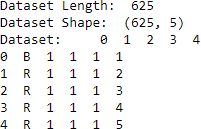
Using Gini Index
Using Entrop
Sample Viva Questions:
1.What are decision trees?
Decision trees are a type of machine learning algorithm that can be used for both classification and regression tasks. They work by partitioning the data into smaller and smaller subsets based on certain criteria. The final decision is made by following the path through the tree that is most likely to lead to the correct outcome.
2. How do decision trees work?
Decision trees work by recursively partitioning the data into smaller subsets. At each partition, a decision is made based on a certain criterion, such as the value of a particular feature. The data is then partitioned again based on the value of a different feature, and so on. This process continues until the data is divided into a number of subsets that are each relatively homogeneous.
3. How do you implement a decision tree in Python?
There are several libraries available for implementing decision trees in Python. One popular library is scikit-learn. To implement a decision tree in scikit-learn, you can use the DecisionTreeClassifier class. This class has several parameters that you can set, such as the criterion for splitting the data and the maximum depth of the tree.
4. How do you evaluate the performance of a decision tree?
There are several metrics that you can use to evaluate the performance of a decision tree. One common metric is accuracy, which is the proportion of predictions that the tree makes correctly. Another common metric is precision, which is the proportion of positive predictions that are actually correct. And another common metric is recall, which is the proportion of actual positives that the tree correctly identifies as positive
.
5. What are some of the challenges of using decision trees?
Some of the challenges of using decision trees include:
- Overfitting: Decision trees can be prone to overfitting, which means that they can learn the training data too well and not generalize well to new data.
- Interpretability: Decision trees can be difficult to interpret when they are very deep or complex.
- Feature selection: Decision trees can be sensitive to the choice of
- Pruning: Decision trees can be difficult to prune, which means that it can be difficult to remove irrelevant branches from the tree.