Aim: Implementation of Logistic Regression using sklearn
Program:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Load dataset
diab_df = pd.read_csv("diabetes.csv")
diab_df.head()
# Split dataset into features and target variable
diab_cols = ['Pregnancies', 'Insulin', 'BMI', 'Age', 'Glucose', 'BloodPressure', 'DiabetesPedigreeFunction']
X = diab_df[diab_cols] # Features
y = diab_df.Outcome # Target variable
# Splitting Data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# Model Development and Prediction
logreg = LogisticRegression(solver='liblinear') # Instantiate the model
logreg.fit(X_train, y_train) # Fit the model with data
y_pred = logreg.predict(X_test) # Predicting y_pred
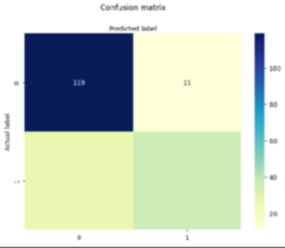
# Model Evaluation using Confusion Matrix
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
cnf_matrix
# Visualizing Confusion Matrix using Heatmap
class_names = [0, 1] # Name of classes
fig, ax = plt.subplots()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
# Create heatmap
sns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu", fmt='g')
ax.xaxis.set_label_position("top")
plt.tight_layout()
plt.title('Confusion Matrix', y=1.1)
plt.ylabel('Actual Label')
plt.xlabel('Predicted Label')
# Confusion Matrix Evaluation Metrics
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
print("Precision:", metrics.precision_score(y_test, y_pred))
print("Recall:", metrics.recall_score(y_test, y_pred))
Output:
Accuracy: 0.8072916666666666
Precision: 0.7659574468085106
Recall: 0.5806451612903226
Sample Viva Questions:
1.What is classification?
Classification is a supervised machine learning problem of predicting which category or class a particular observation belongs to based on its features.Some examples of classification algorithms:
- Logistic regression
- Decision trees
- Random forest
- Artificial neural networks
- XGBoost
2. What is Logistic regression?
Logistic regression is a supervised classification model known as the logit model. It estimates the probability of something occurring, like ‘will buy’ or ‘will not buy,’ based on a dataset of independent variables. The outcome should be a categorical or a discrete value. The outcome can be either a 0 and 1, true and false, yes and no, and so on.
3.Types of logistic regression
So far, we have discussed one type of binary type of logistic regression where the outcome is a 0/1, True/False, and so on. There are two more types:
- Multinomial logistic regression: This type of regression has three or more unordered types of dependent variables, such as cats/dogs/donkeys.
- Ordinal logistic regression: Has three or more ordered dependent variables such as poor/average/ good or high/medium/average.
4. Assumptions of logistic regression
Logistic regression assumes that:
- The response variable is binary or
- The observations or independent variables have very little or no
- There are no extreme
- There is a linear relationship between the predictor variables and the log- odds of the response variable.
5. Logistic regression with Scikit-learn
To implement logistic regression with Scikit-learn, you need to understand the Scikit-learn modeling process and linear regression.
The steps for building a logistic regression include:
- Import the packages, classes, and
- Load the
- Exploratory Data Analysis(EDA).
- Transform the data if
- Fit the classification
- Evaluate the performance